
Filtrar datos con GraphQL y Prisma fue un aprendizaje grande para mí, así que quiero enfocar el artículo en estos temas. Pero primero detallemos la pila de softwares con los que estuve trabajando en los últimos meses. He estado trabajando con React, Apollo, GraphQL y Prisma. Aprender sobre estas 4 capas de programación, puedes crear aplicaciones desde el click del usuario (React y Apollo) hasta manipular y guardar datos en la base de datos (Prisma).
Sin embargo, quiero enfocar este escrito en GraphQL y Prisma porque aunque estaba familiarizada con lenguajes back-end, sólo había podido imitar código ya creado. En otras palabras, no me había sentado a entender cómo funcionan.
Llegué a un bloqueo masivo cuando me tocó trabajar con la función de búsqueda para un producto digital que estoy ayudando a desarrollar.
En un principio es fácil poder desarrollar funciones porque los tutoriales, aunque sean con temas complejos, te ofrecen un ejemplo básico de cómo crearlo. Pero, ¿qué pasa cuando ya los ejemplos básicos no son suficientes?
Los artículos que leí sobre hacer búsquedas en la base de datos, describen ejemplos que solamente toman en consideración la búsqueda de términos dentro de un sólo query. A veces estos ejemplos incluían datos anidados.
Mi bloqueo, ¿qué pasa cuando necesito hacer búsquedas en más de un query?
Quiero compartir mi acercamiento completamente erróneo que tuve al trabajar con filtrar múltiples queries con GraphQL y Prisma. Me tomó varios días de lecturas y hacer muchas preguntas, en entender porque ese acercamiento es incorrecto, y cuál es la mejor forma de buscar datos en diferentes queries. Puedes leer la versión en inglés de este artículo aquí.
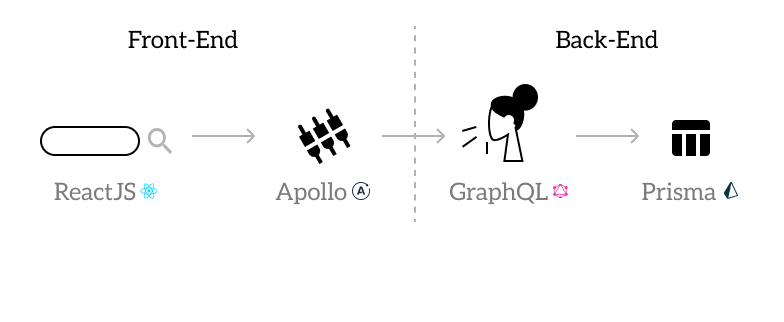
¿Cómo funcionan React, Apollo, GraphQL y Prisma entre sí?
Repasemos como interactúan ReactJs, Apollo, GraphQL, y Prisma en arroz y habichuelas para estar en la misma línea.
ReactJs
Es un marco de referencia del lenguaje Javascript (por eso Js) que se encarga del funcionamiento de la interface entre el usuario y el software. Cuando trabajamos una función como búsqueda en una página web, el funcionamiento de entrada y someter búsquedas, son manejados por ReactJs.
Apollo
Desde el cliente (en alguna función para someter datos desde ReactJs), se comunica con los resolvers de GraphQL para solicitar y recibir informacion en la base de datos, utilizando el lenguaje query de GraphQL.
GraphQL
Es un lenguaje query para APIs que se encarga de controlar los datos que el sitio web recibe. Es donde se escriben las funciones que determinan la datos a mostrar y donde se define el tipo de datos.
Como GraphQL es un lenguaje, hay que decirle a GraphQL qué datos va a buscar y recibir. Estas funciones se llaman resolvers (en inglés porque de verdad no sé como decirlo en español… ¡ayuda por favor!) y son escritas en NodeJs (por eso las extensiones de los archivos de resolvers son tipo js y no graphql).
Es conveniente dado a que el programador tiene la habilidad de especificar los datos que va a recibir de la base de datos, en vez de recibir todos los datos disponible. Es como tener la habilidad de hablarle al servidor para recibir datos específicos en vez de todo.
Prisma
Es una interface entre GraphQL y la base de datos.
Aquí se definen e implementan los diferentes queries de la base de datos.
Los queries se definen en el modelo de datos de Prisma. Luego de varios comandos, Prisma se encarga de auto-generar un archivo que contiene el esquema de los tipos de datos de GraphQL en Prisma. Con este esquema, se busca la información en la base de datos.
En resumidas cuentas…
Contexto del código antes de comenzar a integrar el funcionamiento del buscador
Estamos haciendo búsquedas a multiples queries en la base de datos de un pequeño negocio que maneja equipo de cultivo. Así que, vamos a asumir varios puntos:
1) Hay varios queries disponibles en la base de datos
Significa que los esquemas de tipos de datos tanto en Prisma como GrapQL están definidos. Ejemplo de un archivo prisma/datamodel.prisma que define el esquema de los datos:
type Company { id: ID! @id name: String logo: String location: String } type Equipment { id: ID! @id contact: [User!] model: String serialNo: String company: Company dueDate: DateTime } type User { id: ID! @id firstName: String lastName: String email: String @unique password: String }Mientras que en GraphQL un archivo server/src/schema.graphql, con solucionadores (“resolvers”) definidos y datos importados del archivo Prisma es:
# import User from "./generated/prisma.graphql"
# import Equipment from "./generated/prisma.graphql"
# import Company from "./generated/prisma.graphql"
type Query {
users: [User]!
equipment: [Equipment!]!
company(id: ID!): Company
}Donde el resolver company requiere (! = “es requerido ó no puede ser nulo”) el argumento id para retornar el dato tipo Company.
Mientras que los resolvers users y equipment no requieren algún argumento para retornar un valor. El resolver users tiene que retornar datos tipo User, y el resolver equipment tiene que retornar datos tipo Equipment.
A su vez Equipment debe ser una matriz de valores no nulos. Tampoco la matriz puede ser nula.
2) Las funciones que extraen datos están definidas para los queries mencionados
En buen Spanglish, los query resolvers están definidos. Así que el archivo sever/src/resolvers/Query.js se vería algo así:
const Query = {
users: (parent, args, ctx, info) => {
return ctx.db.query.users(null, info)
},
equipment: (parent, args, ctx, info) => {
return ctx.db.query.equipment(null, info)
},
company: (parent, { id }, ctx, info) => {
return ctx.db.query.company({ where: { id } }, info)
},
}
module.exports = {
Query,
}El resolver del query company deben recibir un argumento tipo id. Estos resolvers van a retornar el query filtrado por el id.
Los resolvers de los queries user y equipment no tienen definido algún argumento para filtrar datos, por lo que va a devolver una matriz de todo el query.
3) Los queries que solicitadas por el front-end tienen datos anidados (“nested”)
Aquí un ejemplo de un query equipment solicitado por Apollo:
import gql from 'graphql-tag';
export default gql`
query Equipment {
equipment {
id
contacts {
id
fistName
lastName
email
}
model
serialNo
dueDate
company {
id
name
}
}
}
`;Otro ejemplo de un query, en este caso company solicitado por Apollo:
import gql from 'graphql-tag';
export default gql`
query Company ($id: ID!) {
company (id: $id) {
id
name
logo
}
}
`;Por último, el ejemplo del query users solicitado por Apollo:
import gql from 'graphql-tag';
export default gql`
query Users {
users {
id
email
firstName
lastName
company {
id
name
logo
}
}
}
`;Filtrando datos utilizando GraphQL y Prisma
¿Recuerdas el query company que definimos anteriormente? Este query es filtrado por el argumento id. Aquí tenemos un ejemplo básico de filtrar en GraphQL. Documentación sobre esto se puede conseguir fácilmente:
const Query = {
company: (parent, { id }, ctx, info) => {
return ctx.db.query.company({ where: { id } }, info)
},
}
module.exports = {
Query,
}Si queremos buscar el id en los diferentes componentes de Company, el código del resolver sería algo como:
const Query = {
company: (parent, { id }, ctx, info) => {
where = {
OR: [
{ id_contains: id },
{ name_contains: id },
{ logo_contains: id },
]
}
return ctx.db.query.company({ where }, info)
},
}
module.exports = {
Query,
}La mayoría de los artículos sobre filtrar en GraphQL llegan hasta este punto. Donde solamente se discute filtrar un query.
Pero, ¿qué pasa cuando necesito hacer búsquedas en más de un query y los datos están anidados?
Enfoque inicial y erróneo para filtrar varios querys
Luego de leer la documentación, mi instinto me dijo que trabajara la filtración de queries editando los resolvers que ya estaban definidos (recordemos el ejemplo anterior).
Pero, me pareció pesada la idea de hacer varios llamados a la base de datos. Con el acercamiento de editar los resolvers, habría que hacer un llamado, desde el front-end, para cada query que quiero filtrar al momento de realizar la búsqueda.
Admito que la funcionalidad de buscador iba a ser implementada luego de que la aplicación tuviese varias funciones validadas. Así que, me cohibí de trabajar en los resolvers que habían sido probados.
También, pensar que la repetición de código se considera un desperdicio, añadió a mi razonamiento de que crear un nuevo query. El nuevo query estaría compuesto por los queries que quiero filtrar por lo que creí que esa era la forma adecuada de manejar la parte del servidor.
Inicialmente, definí mi nuevo query Feed en el esquema de tipos de Prisma (prisma/datamodel.prisma) así:
type Company {
id: ID! @id
name: String
logo: String
}
type Equipment {
id: ID! @id
contacts: [User!]
model: String
serialNo: String
company: Company
dueDate: DateTime
}
type User {
id: ID! @id
firstName: String
lastName: String
email: String @unique
password: String
company: Company
}
type Feed {
users: [User]!
company(id: ID!): Company
equipment: [Equipment]!
}Después generé automáticamente el archivo de Prisma. Luego, importé mi nuevo query Feed al esquema de datos de GraphQL (server/src/schema.graphql) así:
# import User from "./generated/prisma.graphql"
# import Equipment from "./generated/prisma.graphql"
# import Company from "./generated/prisma.graphql"
# import Feed from "./generated/prisma.graphql"
type Query {
users: [User]!
equipment: [Equipment!]!
company(id: ID!): Company
feed(id: ID!, filter: String!): Feed
}También, con el archivo auto-generado de Prisma identifiqué las condiciones que puedo utilizar para buscar datos en Prisma. Por eso, trabajé el resolver feed (sever/src/resolvers/Query.js) así:
const Query = {
users: (parent, args, ctx, info) => {
return ctx.db.query.users(null, info)
},
equipment: (parent, args, ctx, info) => {
return ctx.db.query.equipment(null, info)
},
company: (parent, { id }, ctx, info) => {
return ctx.db.query.company({ where: { id } }, info)
},
feed: async (parent, { id, filter }, ctx, info) => {
const company = await ctx.db.query.company({
where: {
AND: [
{ id },
OR: [
{ name_contains: filter },
{ logo_contains: filter },
],
],
},
}, info);
const equipment = await ctx.db.query.equipment({
where: {
OR: [
{ model_contains: filter },
{ serialNo_contains: filter },
{ dueDate_contains: filter },
{ company_some: {
OR: [
{ name_contains: filter },
{ logo_contains: filter },
]
}
}
]
}
}, info);
const users = await ctx.db.query.users({
where: {
OR: [
{ firstName_contains: filter },
{ lastName_contains: filter },
{ email_contains: filter },
]
}
}, info);
return { users, company, equipment } ;
}
}
module.exports = {
Query,
}Por último, el query desde el front-end pide los datos de la siguiente forma:
import gql from 'graphql-tag';
export default gql`
query Feed ($id: ID!, $filter: String) {
feed (id: $id, filter: $filter) {
id
user {
id
email
firstName
lastName
company {
id
name
logo
}
}
company {
id
name
logo
}
equipment {
id
contacts {
id
fistName
lastName
email
}
model
serialNo
dueDate
company {
id
name
logo
}
}
}
}
`;Como resultado de este compuesto de códigos, pude obtener datos de los 3 queries que estaba buscando. Pero los datos que recibía estaban incompletos. No podía accesar los datos de los queries que están anidados. En este caso los datos de contacts y company dentro de equipment. Solamente me salía el tipo de dato (como bien estaban definidos en los esquemas) pero el valor era nulo.
¿Por qué este enfoque no es el adecuado?
Mirando la documentación y preguntas frecuentes sobre este tema en las redes, la razón básica por la cual los datos a los que deberías accesar son nulos es porque no estas pasando la estructura de los datos correctamente.
Pero, ¿cómo debería ser la estructura correcta de Feed, si le estamos pasando los tipos de datos correctos?
Los queries tienen records atados a ellos en la base de datos. Estos records se identifican por un id asignado. Para asignar estos ids, hay que crear una función para que permita mutar (mutation) el query (crear id) y pueda guardar los datos asignados al record en la base de datos.
Así que, hay que crear una mutación de Feed y conectar los datos de los queries User, Company, y Equipment. Esto significa que hay que crear y guardar en la base de datos un récord tipo Feed nuevo cada vez que se haga una nueva búsqueda.
¡Imagínate cuan cargada va a estar la base de datos si por cada búsqueda que hagas se guardan los queries que combinastes (User, Company, Equipment) para definirlos como tipo Feed!
Sería demasiado costoso e innecesario mantener algo así. Además, GraphQL pierde su poder si se utiliza de esa manera.
Entonces, ¿cuál sería un método adecuado para llevar a cabo búsquedas en multiples queries?
Me parece un poco obvio ahora, pero la filtración de queries se trabaja en… ta dá…. el mismo query. Por lo que mi instinto de añadir la capacidad de filtrar a los resolvers que ya estaban definidos es un mejor acercamiento.
Hay que hacer llamados individuales a cada query desde el front-end para hacer una búsqueda en diferentes queries de la base de datos. Apollo se encarga de hacer los llamados a los resolvers de GraphQL que filtran datos para que la respuesta sea lo mas esbelta posible.
No tenemos que definir un nuevo query para hacer una búsqueda en múltiples queries. Así que, volvemos a definir el prisma/datamodel.prisma de la siguiente forma:
type Company {
id: ID! @id
name: String
logo: String
}
type Equipment {
id: ID! @id
contacts: [User!]
model: String
serialNo: String
dueDate: DateTime
company: Company
}
type User {
id: ID! @id
fistName: String
lastName: String
email: String @unique
password: String
company: Company
}También volvemos a editar el esquema de datos de GraphQL (server/src/schema.graphql) eliminando la definición de tipo Feed y añadiendo el parámetro filter a cada query:
# import User from "./generated/prisma.graphql"
# import Equipment from "./generated/prisma.graphql"
# import Company from "./generated/prisma.graphql"
type Query {
users(filter: String): [User]!
equipment(filter: String): [Equipment!]!
company(id: ID!, filter: String): Company
}Por otro lado, el resolver de Feed que esta definido en sever/src/resolvers/Query.js se elimina. Los demás resolvers se editan para filtrar datos de forma condicional:
const Query = {
users: (parent, { filter }, ctx, info) => {
const where = null;
if (filter) {
where = {
OR: [
{ firstName_contains: filter },
{ lastName_contains: filter },
{ email_contains: filter },
]
}
}
return ctx.db.query.user({ where }, info)
},
equipment: (parent, { filter }, ctx, info) => {
const where = null;
if (filter) {
where = {
OR: [
{ model_comntains: filter },
{ serialNo_contains: filter },
{ company_some: {
OR: [
{ name_contains: filter },
{ logo_contains: filter },
]
},
},
]
},
}
return ctx.db.query.equipment(null, info)
},
company: (parent, { id, filter }, ctx, info) => {
const where = { id };
if (filter) {
where = {
AND: [
{ id },
{
OR: [
{ name_contains: filter },
{ logo_contains: filter },
]
},
]
},
}
return ctx.db.query.company({ where }, info)
},
}
module.exports = {
Query,
}Y los queries que el front-end solicita:
import gql from 'graphql-tag';
export default gql`
query Equipment($filter: String) {
equipment(filter: $filter) {
id
contacts {
id
firstName
lastName
email
}
model
serialNo
dueDate
company {
id
name
}
}
}
`;import gql from 'graphql-tag';
export default gql`
query Company ($id: ID!, $filter: String) {
company (id: $id, filter: $filter) {
id
name
logo
}
}
`;import gql from 'graphql-tag';
export default gql`
query Users($filter: String) {
users(filter: $filter){
id
email
firstName
lastName
company {
id
name
logo
}
}
}
`;Ahora sí debería de resultar en recibir todos los resultados aunque estén anidados.
Ufff… ¡terminamos!
¡Gracias por leer y todo esto! 🙌🎉
Me tomó muchísimo llegar a esta conclusión. Si te puedo ahorrar horas o dias al leer este artículo, siento que cumplí una misión.
Puedes obtener notificaciones de nuevos artículos directamente a tu buzón electrónico registrándote en el siguiente enlace.
Artículos relacionados
Los siguientes artículos de CTRL-Y están relacionados a este escrito. ¡Deberías de echarles un vistazo!:
- Pruebas al API con Mocha
- Arquitectura de capas para NodeJS.
- Las partes generales del lenguaje de programación
- HTML para Principiantes
- Atributos de etiquetado para HTML
- HTML: Anidar etiquetas
- Una mañana en el terminal Mac de una desarrolladora de front-end
Punto aparte – Una lista de reproducción para tí
Este artículo lo escribí escuchando Ladybug Podcast. Es raro de mi parte escuchar podcasts mientras escribo pero los temas de las chicas me motivaron a escribir este artículo. Ladybug Podcast es un programa dirigido a desarrolladores de web. Es presentado por las chicas Kelly Vaughn, Ali Spittel, y Emma Wedekind. Aunque escuché los episodios del podcast de manera seguida, comparto el episodio dedicado a GraphQL. También lo escuché mientras escribía este artículo.
Hola como estas me parece muy interesante este blog te felicito que buena información.
¡Muchas gracias! Trato de publicar algo una vez al mes, así que pendiente para más contenido.